Java集合框架(十七):LinkedList 源码分析
LinkedList 简述
🌂Java LinkedList是List和Deque接口的实现。
🌂在内部,LinkedList 是采用双向链表实现的,它包含一个很重要的内部类 Node。Node是双向链表节点所对应的数据结构,它包括的属性有:当前节点所包含的值,上一个节点,下一个节点。
🌂它支持重复元素,并且可以添加任意数量的null元素。
🌂它以插入顺序存储或维护它的元素。
🌂它不是线程安全的,我们可以使用Collections.synchronizedList(new LinkedList(…));方法创建一个同步的链表。
🌂在Java应用中,LinkedList 可以用作List,LIFO(后进先出)的栈或FIFO(先进先出)的队列。
🌂它没有实现RandomAccess接口。 所以我们只能按顺序访问元素。 它不支持随机访问元素。
🌂当我们尝试从 LinkedList 访问元素时,根据元素可用的位置搜索该元素从LinkedList的开头或结尾开始。
🌂我们可以使用ListIterator来迭代LinkedList元素。
🌂从LinkedList的实现方式中可以发现,它不存在LinkedList容量不足的问题。
🌂LinkedList 的克隆函数(clone()),是将全部元素克隆到一个新的LinkedList对象中。
🌂LinkedList 实现java.io.Serializable。当写入到输出流时,先写入“容量”,再依次写入“每一个节点保护的值”;当读出输入流时,先读取“容量”,再依次读取“每一个元素”。
🌂由于LinkedList实现了Deque,而Deque接口定义了在双端队列两端访问元素的方法。提供插入、移除和检查元素的方法。每种方法都存在两种形式:一种形式在操作失败时抛出异常,另一种形式返回一个特殊值(null 或 false,具体取决于操作)
🌂从Java 8开始,我们可以将LinkedList 转换为 Stream,反之亦然。
🌂Java 9 添加了几个工厂方法来创建一个Immutable LinkedList。
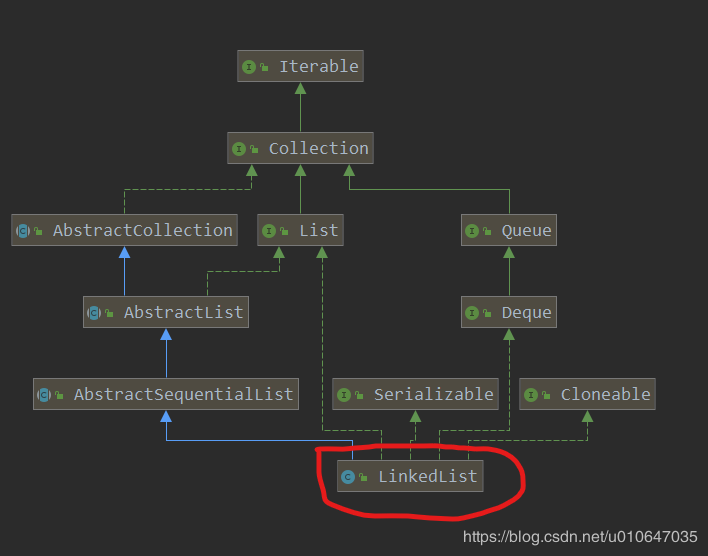
LinkedList 类图
🌂众所周知,Java LinkedList是List实现类之一。
java.util.LinkedList 继承了 AbstractSequentialList 并实现了List , Deque , Cloneable 以及Serializable 接口
1 | public class LinkedList<E> |
LinkedList 内部结构
LinkedList内部结构是一个双向链表
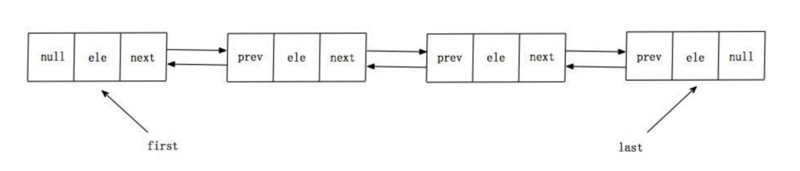
每一个节点都是一个Node 对象,由三个元素组成
1 | private static class Node<E> { |
LinkedList 成员变量LinkedList 成员变量
size 链表的节点数量size 链表的节点数量
初始化链表的长度为0
1 | transient int size = 0; |
first 指向第一个节点的指针first 指向第一个节点的指针
1 | /** |
last 指向最后一个节点的指针last 指向最后一个节点的指针
1 | /** |
LinkedList 构造函数LinkedList 构造函数
LinkedList()LinkedList()
构造一个空列表。
1 | public LinkedList() {} |
LinkedList(Collection<? extends E> c)
1 | /** |
LinkedList 方法LinkedList 方法
由于LinkedList实现了Deque,而Deque接口定义了在双端队列两端访问元素的方法。提供插入、移除和检查元素的方法。每种方法都存在两种形式:一种形式在操作失败时抛出异常,另一种形式返回一个特殊值(null 或 false,具体取决于操作)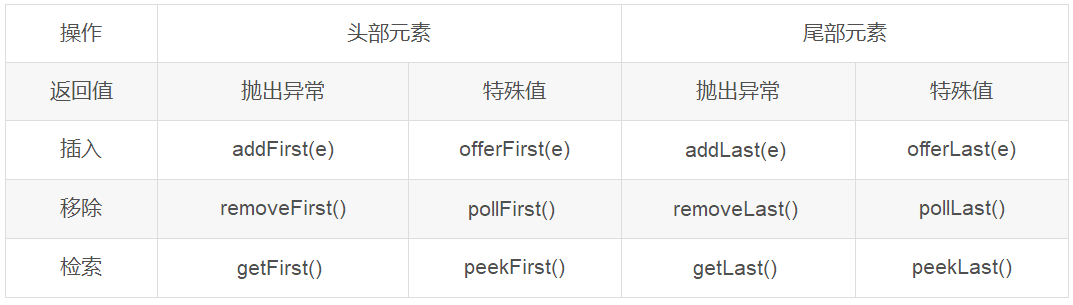
LinkedList 可以作为 FIFO(先进先出)的队列,作为FIFO的队列时,下面的方法是等价的
| 队列方法 | 等价方法 |
|---|---|
| add(e) | addLast(e) |
| offer(e) | offerLast(e) |
| remove() | removeFirst() |
| poll() | pollFirst() |
| element() | getFirst() |
| peek() | peekFirst() |
LinkedList 可以作为 LIFO(后进先出)的栈,作为LIFO的栈时,下面的方法是等价的
| 栈方法 | 等价方法 |
|---|---|
| push(e) | addFirst(e) |
| pop() | removeFirst() |
| peek() | peekFirst() |
LinkedList 获取元素
public E get(int index)
获取指定索引处节点的元素,首先对指定索引进行越界检查,如果未越界返回相应位置node节点的元素;否则,抛出 IndexOutOfBoundsException 异常
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50/**
* 返回此列表中指定位置的元素。
*
* @param index 要返回的元素的索引值
* @return 列表中指定位置的元素
* @throws IndexOutOfBoundsException
*/
public E get(int index) {
//索引越界检查
checkElementIndex(index);
return node(index).item;
}
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* 判断参数是否是现有元素的索引。
*/
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
/**
* 构造一个IndexOutOfBoundsException详细消息。
*
*/
private String outOfBoundsMsg(int index) {
return "Index: "+index+", Size: "+size;
}
/**
* 返回指定元素索引处的(非null)节点。
*/
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
public E getFirst()public E getFirst()
返回此列表中的第一个元素。
1 | /** |
public E getLast()public E getLast()
返回此列表中最后一个元素
1 | /** |
public int indexOf(Object o)public int indexOf(Object o)
返回此列表中第一次出现的指定元素的索引,如果此列表不包含该元素,则返回-1。
如果需要检索的元素是null,对元素链表进行遍历,返回x的元素为空的位置
如果需要检索的元素不是null,对元素的链表遍历,直到找到相同的元素,返回元素下标
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public int indexOf(Object o) {
int index = 0;
//如果检索的元素为null
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
//如果检索的元素不为null
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
public int lastIndexOf(Object o)public int lastIndexOf(Object o)
返回此列表中指定元素最后一次出现的索引,如果此列表不包含该元素,则返回-1。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public int lastIndexOf(Object o) {
int index = size;
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (x.item == null)
return index;
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (o.equals(x.item))
return index;
}
}
return -1;
}
public E peek()
检索并返回此列表的第一个元素,但不删除该元素。如果列表为空,则返回null
1
2
3
4
5
6
7/**
* 检索但不删除此列表的头部(第一个元素)。
*/
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
public E peekFirst() 同 peek()public E peekFirst() 同 peek()
public E peekLast()public E peekLast()
检索但不删除此列表的最后一个元素,如果此列表为空,则返回null。
1
2
3
4public E peekLast() {
final Node<E> l = last;
return (l == null) ? null : l.item;
}
public E element()public E element()
与peek()相同的地方都是访问链表的第一个元素,不同是element元素在链表为null的时候会报空指针异常
1
2
3public E element() {
return getFirst();
}
LinkedList 增加元素LinkedList 增加元素
public boolean add(E e) 等价 addLast
添加指定元素至list末尾,等价于 addLast
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37/**
* 添加指定元素至list末尾
*
* 该方法等价与addLast
*
* @param e 添加到列表的元素
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
linkLast(e);
return true;
}
/**
* 链接e作为最后一个元素
*/
void linkLast(E e) {
//创建临时节点l初始化为尾节点
final Node<E> l = last;
//初始化新节点,前驱节点为l,后继暂为null
final Node<E> newNode = new Node<>(l, e, null);
//由于是在链表尾部插入节点,那么新节点就作为尾节点
last = newNode;
/**
* l节点作为newNode节点的前驱节点。
* 如果l为空,那么newNode前驱节点为空。
* 在双向链表中,前驱节点为空,那么该节点为头节点。
*/
if (l == null)
first = newNode;
else
// 如果不是的话,就让该节点的next 指向新的节点
l.next = newNode;
//插入节点后,链表的长度加1
size++;
modCount++;
}
public void add(int index, E element)
将元素插入指定位置,首先通过index获取当前对应的定位节点。如果下标对应的定位节点就是尾节点,那么直接使用linkLast方法在链表尾部插入节点。如果对应的定位节点不是尾节点,就插入到index节点的前面。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69 /**
* 在链表的指定位置插入指定元素
* 将当前位于该位置的元素(如果有)和任何后续元素向右移动。
*
* @param index 指定元素插入位置的索引
* @param element 待插入的元素
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public void add(int index, E element) {
// 先检查索引是否在链表的范围内。
checkPositionIndex(index);
// 如果索引等于链表长度,那么直接采用尾插法的linkLast方法。
if (index == size)
linkLast(element);
else
//否则就在指定位置的非空节点之前插入元素
linkBefore(element, node(index));
}
private void checkPositionIndex(int index) {
// 下标越界检查
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* 判断参数是否是有效位置
*/
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
/**
* 链接e作为最后一个元素。
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
/**
* 在节点succ作为通过下标索引在链表中查询出来的对应的节点。
* e值包装的节点插入到succ节点之前。
*/
void linkBefore(E e, Node<E> succ) {
//succ节点的前驱为pred
final Node<E> pred = succ.prev;
//初始化新节点前驱为pred,后继为succ,意思就是想在pred和succ节点之间插入newNode节点
final Node<E> newNode = new Node<>(pred, e, succ);
//到这步,newNode已经确立了,后继节点为succ。succ节点的前驱为newNode。
succ.prev = newNode;
//如果pred为空,那么newNode的前驱节点为空,可以确定newNode为头节点。
if (pred == null)
first = newNode;
else
/* 如果pred不为空,则确定了pred节点后继为newNode,之前已经确
* 定newNode的前驱为pred,这样pred和newNode就确立关系了。
*/
pred.next = newNode;
size++;//新增节点,长度更新为原来长度加1
modCount++;
}
public void addFirst(E e)
在此列表的开头插入指定的元素。要添加 元素至链表的头部,需要先找到first节点,如果first节点为null,也就说明没有头节点,如果不为null,则头节点的prev节点是新插入的节点。
如果双向链表为空,那么插入节点作为头节点,如果双向链表不为空,那么插入节点作为头结点的前驱节点。
1 | /** |
public void addLast(E e) 等价 add
将指定的元素追加到此列表的末尾。如果双向链表为空,那么直接新节点作为头节点。如果双向链表不为空,那么在尾节点后面插入新节点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30/**
* 将指定的元素追加到此列表的末尾。
*
* 此方法等价与add
*
* @param 准备添加的元素
*/
public void addLast(E e) {
linkLast(e);
}
//采用双向链表尾插法的方式插入元素
void linkLast(E e) {
//创建临时节点l初始化为尾节点(那么其后继节点为null,前驱节点不为空)。
final Node<E> l = last;
//初始化新节点,前驱节点为l,后继暂为null
final Node<E> newNode = new Node<>(l, e, null);
//由于是在链表尾部插入节点,那么新节点就作为尾节点。
last = newNode;
/**
* l节点作为newNode节点的前驱节点。
* 如果l为空,那么newNode前驱节点为空。
* 在双向链表中,前驱节点为空,那么该节点为头节点。
*/
if (l == null)
first = newNode;
else
l.next = newNode;
size++;//再插入节点后,链表的长度加1
modCount++;
}
public boolean addAll(Collection<? extends E> c)
将指定集合中的所有元素按指定集合的迭代器返回的顺序附加到此列表的末尾。 如果在操作正在进行时修改了指定的集合,则此操作的行为是不确定的。
1
2
3public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
public boolean addAll(int index, Collection<? extends E> c)
将指定集合中的所有元素按指定集合的迭代器返回的顺序附加到此列表的末尾。 如果在操作正在进行时修改了指定的集合,则此操作的行为是不确定的。
插入一个Collection 的集合,没有指定插入元素的位置,默认是向链表的尾部进行链接。
如果指定了插入位置,首先会进行数组越界检查,然后会把集合转换为数组,在判断数组的大小是否为0,为0返回,不为0,继续下面操作
然后遍历数组,首先生成对应的节点,最后对节点进行链接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62/**
* @param index 插入列表指定位置的索引
* @param c 包含要添加到此列表的元素的集合
* @return {@code true} if this list changed as a result of the call
* @throws IndexOutOfBoundsException 下标越界异常
* @throws NullPointerException 如果指定的集合为null,则抛出空指针异常
*/
public boolean addAll(int index, Collection<? extends E> c) {
//判断下标元素是否在链表的长度范围之内
checkPositionIndex(index);
//将集合c转换成Object数组
Object[] a = c.toArray();
//插入元素的数量
int numNew = a.length;
//如果Object数组长度为0,那么就返回添加失败
if (numNew == 0)
return false;
//pred节点为succ节点的前驱
Node<E> pred, succ;
//如果下标等于链表的长度时,pred为尾节点,succ指向为空
if (index == size) {
succ = null;
pred = last;
} else {
/* 如果下标不等于链表长度,node方法就是用来通过下标索引获
* 取链表中的对应的节点对象。
*/
succ = node(index);
pred = succ.prev;
}
//遍历数组,创建node节点
for (Object o : a) {
//将遍历的值包装成节点Node,初始化前驱节点为pred,后继节点为null
E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
//如果前驱节点为空,那么肯定是头节点
if (pred == null)
first = newNode;
else
//否则不是头节点,那么前驱的后继节点为当前节点,其实就是类似于链表的插入节点操作。
pred.next = newNode;
pred = newNode;
}
/*
* 因为pred节点是succ节点的前驱节点,反之succ是pred的后继节点.
* 如果succ为空,说明pred为尾节点。
*/
if (succ == null) {
last = pred;
} else {
/*
如果succ不是尾节点,那么只要保证pred节点是succ节点的前驱
* 节点、succ是pred的后继节点这种双向链表的关系
*/
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
public boolean offer(E e) 等价于 add
1 | public boolean offer(E e) { |
public boolean offerFirst(E e) 等价于 addFirst(E e)
1 | public boolean offerFirst(E e) { |
public boolean offerLast(E e) 等价于 addLast(E e)
1 | public boolean offerLast(E e) { |
public void push(E e) 等价于 addFirst(E e)
1 | public void push(E e) { |
LinkedList 删除元素
public E remove()
检索并删除此列表的第一个元素
1 | /** |
public E remove(int index)
删除此列表中指定位置的元素。 将任何后续元素向左移位。返回从列表中删除的元素。
1 | /** |
public boolean remove(Object o)
从此列表中删除指定元素的第一个匹配项(如果存在)。 如果此列表不包含该元素,则不会更改。
/**
*
* @param o 要从此列表中删除的元素(如果存在)
* @return {@code true} 如果此列表包含指定的元素,则返回true
*/
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
public E removeFirst()
删除并返回此列表的第一个元素
1
2
3
4
5
6
7
8
9
10
11
12/**
* 删除并返回此列表的第一个元素
*
* @return 此列表第一个元素
* @throws NoSuchElementException 如果列表为空
*/
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
public E removeLast()
删除并返回此列表的最后一个元素
1 | /** |
public boolean removeFirstOccurrence(Object o)
删除此列表中第一次出现的指定元素(从头到尾遍历列表时)。 如果列表不包含该元素,则不会更改。
1 | /** |
public boolean removeLastOccurrence(Object o)
删除此列表中最后一次出现的指定元素(从头到尾遍历列表时)。 如果列表不包含该元素,则不会更改。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23/**
* @param o 从列表中删除的指定元素
* @return 如果列表包含指定的元素返回true
* @since 1.6
*/
public boolean removeLastOccurrence(Object o) {
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
public E poll()
检索并删除此列表的第一个元素,如果此列表为空,则返回null。
1 |
|
public E pollFirst()
检索并删除此列表的第一个元素,如果此列表为空,则返回null。
1
2
3
4
5
6
7
8/**
* @return 返回此列表的第一个元素,如果列表为空则返回null
* @since 1.6
*/
public E pollFirst() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
public E pollLast()
检索并删除此列表的最后一个元素,如果此列表为空,则返回null。
1
2
3
4
5
6
7
8/**
* @return 此列表的最后一个元素,如果此列表为空,则返回null。
* @since 1.6
*/
public E pollLast() {
final Node<E> l = last;
return (l == null) ? null : unlinkLast(l);
}
public E pop() 等价于 removeFirst()
弹出此列表所代表的堆栈中的元素。 换句话说,删除并返回此列表的第一个元素。
此方法等同于removeFirst()。
1
2
3
4
5
6
7
8/**
* @return 此列表所代表的栈顶元素
* @throws NoSuchElementException 如果列表为空
* @since 1.6
*/
public E pop() {
return removeFirst();
}
public void clear()
从此列表中删除所有元素。 此调用返回后,列表将为空。通过遍历断开每个节点之间的链接并设置每个节点为null,以帮助GC回收。
1
2
3
4
5
6
7
8
9
10
11
12public void clear() {
for (Node<E> x = first; x != null; ) {
Node<E> next = x.next;
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
first = last = null;
size = 0;
modCount++;
}
LinkedList 其它方法
public boolean contains(Object o)
如果此列表包含指定的元素,则返回true。 当且仅当此列表包含至少一个元素e时才返回true(o == null?e == null:o.equals(e))。
1
2
3
4
5
6
7/**
* @param o 要测试其在此列表中的存在的元素
* @return 如果此列表包含指定的元素,则返回true
*/
public boolean contains(Object o) {
return indexOf(o) != -1;
}
public int size()
返回此列表中的元素数量
1
2
3public int size() {
return size;
}
public E set(int index,E element)
用指定的元素替换此列表中指定位置的元素,并返回被替换的元素
1 | /** |
public ListIterator listIterator(int index)
🌂从列表中的指定位置开始,返回此列表中元素的列表迭代器(按正确顺序)。 遵守List.listIterator(int)的规则。
🌂list-iterator是 fail-fast 的:如果在创建Iterator之后的任何时候对列表进行结构修改,除了通过list-iterator自己的remove或add方法之外,list-iterator将抛出ConcurrentModificationException。
1
2
3
4
5
6
7
8
9
10/**
* @param 从list-iterator返回的第一个元素的索引(通过调用next)
* @return 从列表中的指定位置开始,返回此列表中元素的ListIterator
* @throws IndexOutOfBoundsException {@inheritDoc}
* @see List#listIterator(int)
*/
public ListIterator<E> listIterator(int index) {
checkPositionIndex(index);
return new ListItr(index);
}
public Iterator descendingIterator()
以相反的顺序返回此双端队列中元素的迭代器。 元素将按从尾部 到 头部 的顺序返回。
1 | /** |
public Object clone()
返回此LinkedList的浅副本。(元素本身未被克隆。)
1
2
3
4
5
6
7
8
9
10
11
12
13
14public Object clone() {
LinkedList<E> clone = superClone();
// Put clone into "virgin" state
clone.first = clone.last = null;
clone.size = 0;
clone.modCount = 0;
// Initialize clone with our elements
for (Node<E> x = first; x != null; x = x.next)
clone.add(x.item);
return clone;
}
public Object[] toArray()
以适当的顺序(从第一个元素到最后一个元素)返回包含此列表中所有元素的数组。
返回的数组将是“安全的”,因为此列表不会保留对它的引用。 (换句话说,此方法必须分配一个新数组)。 因此调用者可以自由修改返回的数组。
1
2
3
4
5
6
7public Object[] toArray() {
Object[] result = new Object[size];
int i = 0;
for (Node<E> x = first; x != null; x = x.next)
result[i++] = x.item;
return result;
}
public T[] toArray(T[] a)
🌂以适当的顺序返回包含此列表中所有元素的数组(从第一个元素到最后一个元素); 返回数组的运行时类型是指定数组的运行时类型。 如果列表适合指定的数组,则返回其中。 否则,将使用指定数组的运行时类型和此列表的大小分配新数组。
🌂如果列表适合指定的数组,并且有空余空间(即,数组的元素多于列表),则紧跟在列表末尾之后的数组中的元素将设置为null。 仅当调用者知道列表不包含任何null元素时,这在确定列表长度时很有用。
🌂与toArray()方法一样,此方法充当基于数组的API和基于集合的API之间的桥梁。 此外,该方法允许精确控制输出阵列的运行时类型,并且在某些情况下可以用于节省分配成本。
🌂假设x是已知仅包含字符串的列表。 以下代码可用于将列表转储到新分配的String数组中:
String[] y = x.toArray(new String[0]);
请注意,toArray(new Object [0])在功能上与toArray()相同。
1
2
3
4
5
6
7
8
9
10
11
12
13
14public <T> T[] toArray(T[] a) {
if (a.length < size)
a = (T[])java.lang.reflect.Array.newInstance(
a.getClass().getComponentType(), size);
int i = 0;
Object[] result = a;
for (Node<E> x = first; x != null; x = x.next)
result[i++] = x.item;
if (a.length > size)
a[size] = null;
return a;
}
public Spliterator spliterator()
在此列表中的元素上创建一个 late-binding 和 fail-fast 的Spliterator。
1 |
|
 微信
微信 支付宝
支付宝








