1、HashTable 简介 和 HashMap 一样,Hashtable 也是一个散列表 。从Java 1.2开始,这个类被改进以实现Map接口,使其成为Java Collections Framework的成员。 与新的集合实现不同,Hashtable是同步的。 如果不需要线程安全实现,建议使用HashMap代替Hashtable。 如果需要线程安全的高度并发实现,那么建议使用ConcurrentHashMap代替Hashtable。
该类实现了一个哈希表,它将键映射到值。 任何非null对象都可以用作键或值。要成功存储和检索哈希表中的对象,用作键的对象必须实现hashCode方法和equals方法。
通常,默认负载系数(0.75)在时间和空间成本之间提供了良好的折衷。 较高的值会减少空间开销,但会增加查找条目的时间成本(这反映在大多数Hashtable操作中,包括get和put)。
初始容量控制了浪费空间和重新运算操作的需要之间的权衡,这是非常耗时的。 如果初始容量大于Hashtable将包含的最大条目数除以其加载因子,则不会发生重复操作。 但是,将初始容量设置得太高会浪费空间。
如果要将多个元素设置为Hashtable,则创建具有足够容量的初始大小可以更有效地插入元素,而不是根据需要执行自动扩容来扩展表。
1.1、HashTable 定义
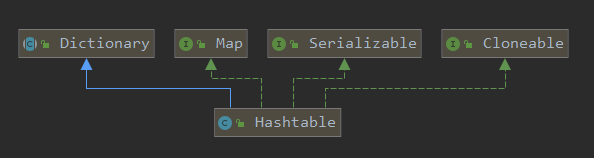
1 2 3 public class Hashtable <K,V> extends Dictionary <K,V> implements Map <K,V>, Cloneable, java.io.Serializable
从源码中,我们可以看出,Hashtable 继承于 Dictionary 类,实现了 Map, Cloneable, java.io.Serializable接口。
其中Dictionary类是任何可将键映射到相应值的类(如 Hashtable)的抽象父类,每个键和值都是对象。
1 Dictionary 源码注释中有这样一句话,NOTE: This class is obsolete. New implementations should implement the Map interface, rather than extending this class.( Dictionary 这个类过时了,新的实现类应该实现Map接口。)
1.2、HashTable 属性 Hashtable 是通过”拉链法”实现的哈希表。它包括几个重要的成员变量:table, count, threshold, loadFactor, modCount。
🌂table:是一个 Entry[] 数组类型,而 Entry(在 HashMap 中有讲解过)实际上就是一个单向链表。哈希表的”key-value键值对”都是存储在Entry数组中的。
🌂count:是 Hashtable 的大小,它是 Hashtable 保存的键值对的数量。
🌂threshold:是 Hashtable 的阈值,用于判断是否需要调整 Hashtable 的容量。threshold 的值=“容量*加载因子”。
🌂loadFactor:是加载因子。
🌂modCount:是用来实现 fail-fast 机制的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public class Hashtable <K,V> extends Dictionary <K,V> implements Map <K,V>, Cloneable, java.io.Serializable { private transient Entry<?,?>[] table;private transient int count;private int threshold;private float loadFactor;private transient int modCount = 0 ; }
其中table中存储的是Entry节点,Entry节点直接采用内部类的方式实现,实现了Map.Entry类,其数据结构源码如下:
1 2 3 4 5 6 private static class Entry <K,V> implements Map .Entry<K,V> { int hash; K key; V value; Entry<K,V> next; }
Entry 节点中存储了元素的hash值,key, value,next引用。至此Hashtable的数据结构从源码就能看出来是数组+链表的方式实现的。
1.3、HashTable 构造方法 1.3.1、Hashtable() 在默认构造方法中,调用了Hashtable(int initialCapacity, float loadFactor)方法,初始Hashtable的容量为11,负载因子为0.75,那么初始阈值就是8。这点和HashMap很不同,HashMap在初始化时,table的大小总是2的幂次方,即使给定一个不是2的幂次方容量的值,也会自动初始化为最接近其2的幂次方的容量。
1 2 3 4 5 6 public Hashtable () { this (11 , 0.75f ); }
1.3.2、Hashtable(int initialCapacity) 使用指定的初始容量和默认加载因子(0.75)构造一个新的空哈希表。
1 2 3 4 5 6 7 8 9 10 public Hashtable (int initialCapacity) { this (initialCapacity, 0.75f ); }
1.3.3、Hashtable(int initialCapacity, float loadFactor) 使用指定的初始容量和指定的加载因子构造一个新的空哈希表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public Hashtable (int initialCapacity, float loadFactor) { if (initialCapacity < 0 ) throw new IllegalArgumentException ("Illegal Capacity: " + initialCapacity); if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException ("Illegal Load: " +loadFactor); if (initialCapacity==0 ) initialCapacity = 1 ; this .loadFactor = loadFactor; table = new Entry <?,?>[initialCapacity]; threshold = (int )Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1 ); }
1.3.4、Hashtable(Map<? extends K,? extends V> t) 构造一个新的哈希表,其具有与给定Map相同的映射。 创建哈希表的初始容量足以容纳给定Map中的映射和默认加载因子(0.75)。
1 2 3 4 5 6 7 8 9 10 11 public Hashtable (Map<? extends K, ? extends V> t) { this (Math.max(2 *t.size(), 11 ), 0.75f ); putAll(t); }
2、HashTable 源码分析 2.1、put 方法 put方法是同步的,即线程安全的,这点和HashMap不一样,还有具体的put操作和HashMap也存在很大的差别,Hashtable插入的时候是插入到链表头部,而HashMap是插入到链表尾部
put 方法的整体逻辑如下:
🌂判断 value 是否为空,为空则抛出异常;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 public synchronized V put (K key, V value) { if (value == null ) { throw new NullPointerException (); } Entry<?,?> tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF ) % tab.length; @SuppressWarnings("unchecked") Entry<K,V> entry = (Entry<K,V>)tab[index]; for (; entry != null ; entry = entry.next) { if ((entry.hash == hash) && entry.key.equals(key)) { V old = entry.value; entry.value = value; return old; } } addEntry(hash, key, value, index); return null ; } private void addEntry (int hash, K key, V value, int index) { modCount++; Entry<?,?> tab[] = table; if (count >= threshold) { rehash(); tab = table; hash = key.hashCode(); index = (hash & 0x7FFFFFFF ) % tab.length; } @SuppressWarnings("unchecked") Entry<K,V> e = (Entry<K,V>) tab[index]; tab[index] = new Entry <>(hash, key, value, e); count++; }
通过源码,我们可以看出 HashMap 与 Hashtable 计算索引的方式是不一样的:
🌂HashMap 计算索引的方式是h&(length-1),而Hashtable用的是模运算,效率上是低于HashMap的
2.2、get 方法 get方法也是同步的,和HashMap不一样,即线程安全,具体的get操作和HashMap也有区别。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public synchronized V get (Object key) { Entry<?,?> tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF ) % tab.length; for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { return (V)e.value; } } return null ; }
2.3、remove 方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public synchronized V remove (Object key) { Entry<?,?> tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF ) % tab.length; @SuppressWarnings("unchecked") Entry<K,V> e = (Entry<K,V>)tab[index]; for (Entry<K,V> prev = null ; e != null ; prev = e, e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { modCount++; if (prev != null ) { prev.next = e.next; } else { tab[index] = e.next; } count--; V oldValue = e.value; e.value = null ; return oldValue; } } return null ; }
2.4、rehash 方法 Hashtable 的rehash方法是用来扩容哈希表的。Hashtable每次扩容,容量都为原来的2倍加1,而HashMap为原来的2倍。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 protected void rehash () { int oldCapacity = table.length; Entry<?,?>[] oldMap = table; int newCapacity = (oldCapacity << 1 ) + 1 ; if (newCapacity - MAX_ARRAY_SIZE > 0 ) { if (oldCapacity == MAX_ARRAY_SIZE) return ; newCapacity = MAX_ARRAY_SIZE; } Entry<?,?>[] newMap = new Entry <?,?>[newCapacity]; modCount++; threshold = (int )Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1 ); table = newMap; for (int i = oldCapacity ; i-- > 0 ;) { for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) { Entry<K,V> e = old; old = old.next; int index = (e.hash & 0x7FFFFFFF ) % newCapacity; e.next = (Entry<K,V>)newMap[index]; newMap[index] = e; } } }
3、Hashtable 如何保证线程安全 通过Hashtable源码,我们发现对外提供的public方法,几乎全部加上了synchronized关键字。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public synchronized int size () {}public synchronized boolean isEmpty () {}public synchronized Enumeration<K> keys () {}public synchronized Enumeration<V> elements () {}public synchronized boolean contains (Object value) {}public synchronized boolean containsKey (Object key) {}public synchronized V get (Object key) {}public synchronized V put (K key, V value) {}public synchronized V remove (Object key) {}public synchronized void putAll (Map<? extends K, ? extends V> t) {}public synchronized void clear () {}public synchronized Object clone () {}public synchronized String toString () {}public synchronized boolean equals (Object o) {}public synchronized int hashCode () {}
所以从这个特性上看,Hashtable是通过简单粗暴的方式来保证线程安全的额。所以Hashtable的性能在多线程环境下会非常低效。前面介绍的ConcurrentHashMap其实就是Java开发团队为了替换他而开发的,性能提高了不少。
所以建议大家在多线程环境下使用 ConcurrentHashMap,或者用HashMap配合外部锁,例如ReentrantLock来提高效率。
4、Hashtable 与 HashMap 的区别 不同点:
🌂HashMap 继承于 AbstractMap抽象类,Hashtable 继承于Dictionay抽象类
相同点:
🌂HashMap 和 Hashtable 都实现了Map接口
 微信
微信 支付宝
支付宝







